




報酬を用いた強化学習とは?機械学習との違いや実例を解説

「強化学習、報酬って何のこと?」
「強化学習と機械学習って何が違うの?」
と思うことはありませんか?
強化学習を勉強しようとしても、報酬などの用語や、機械学習との違いが難しいですよね。
なかなか強化学習について、理解ができない人は多いのではないでしょうか。
そこで今回は、
- 強化学習の基本
- 強化学習の流れ・手法
- 強化学習の事例
について詳しく解説します。
この記事を読めば、強化学習や報酬について理解を深められます。
ぜひ最後まで読んでみてくださいね。
強化学習の基礎
強化学習は、私達の生活をより豊かにしてくれる技術です。
まずはそんな強化学習とはなにか、基礎から理解していきましょう。
- 強化学習とは
- 強化学習の仕組み
- 強化学習の重要性
それぞれ解説していきます。
1.強化学習とは
強化学習とは、機械学習の一種で、報酬という成果を最大化するために、行動と学習を繰り返す学習方法です。
例えば、経路探索のアルゴリズムを考えた場合、距離の短さを報酬とすることで、できるだけ距離が短い経路を学習していきます。
◯や✕で区別がつけやすい分類などの分野ではなく、過程や行動を評価する場合に有効で、必ずしも大量のデータが必要でないことがメリットです。
2.強化学習の仕組み
強化学習では、学習の対象をエージェント、評価を報酬と呼びます。
ペットである犬のしつけを例とすると、犬がエージェントで、食べ物や誉め言葉が報酬です。
行動に対しての受け取る報酬により、最適な行動を見つけていきます。
3.強化学習の重要性
強化学習には、他の学習方法とは異なる2つのメリットがあります。
- 学習に大量のデータを必要としないこと
- ◯✕で表すことが難しい過程や行動の学習ができること
データを収集するのが難しいケースや、◯✕で区別をつけにくいケースでも適用できる機械学習方法として、とても重要な役割を担っています。
[/list]つまりディープラーニングのほうが、より人間の思考に近い結果を生み出す技術だといえるでしょう。
深層強化学習とは
深層強化学習とは、強化学習とディープラーニングを組み合わせた技術です。
具体的に、
- 現状の確認
- 行動と変化
- 評価と報酬
これらを繰り返しおこなっています。
深層強化学習も、人間の思考に近い技術ですが、その試行錯誤の回数は計り知れません。
数百万間というデータ分析を繰り返しながら、より効率的な結果を導き出します。
エンジニアを目指したいと思った方には、初心者でも確実にプログラミングが身に付く【DMM WEBCAMP】がおすすめ。
プログラミング初心者の受講生が97%以上の【DMM WEBCAMP】では、未経験者コースも用意もされており、安心して学習を進めていくことが可能です。
あなたのライフスタイルに合わせて好きなコースを選択してみてください。
「今の働き方に不満はあるけど、日々の業務が忙しくてゆっくり考える時間がない…」
そんな悩みを持つ方に向けて【DMM WEBCAMP】では無料のキャリア相談を実施しています。
ビデオ通話で相談をすることができるため、仕事で忙しい方でもスキマ時間に気軽にカウンセリングを受けることも可能です!
プロのキャリアカウンセラーと一緒に、今後のキャリアについて考えてみませんか?

強化学習と機械学習、ディープラーニングの違い
強化学習は、機械学習やディープラーニングと同じように使われる場面が多いですが、実際は異なる役割をもっています。
こちらでは、下記項目について解説します。
- 機械学習とは
- ディープラーニングとは
- 強化学習と、ディープラーニングの違い
それぞれ見ていきましょう。
1.機械学習とは
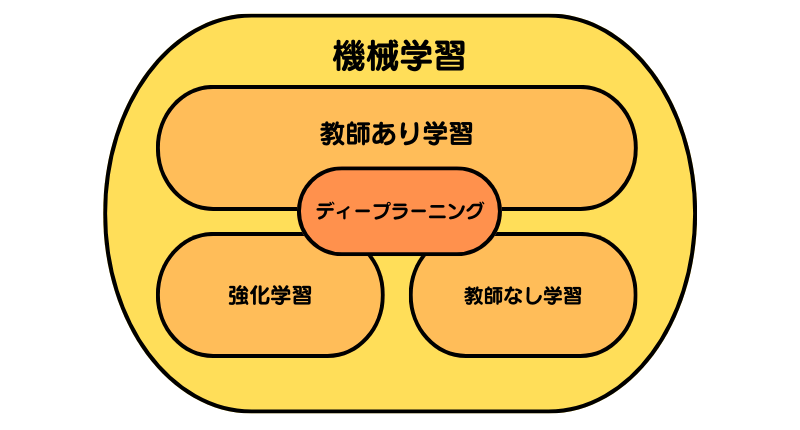
機械学習とは、データを分析する技術のひとつです。
コンピューターが大量のデータを学習し、予測・識別をおこないながらアルゴリズムを自動で構築する技術全般のことをいいます。
この機械学習には、
- 教師あり学習
- 教師なし学習
- 強化学習
の3つの領域が存在します。
つまり「強化学習」は、機械学習の手法のひとつなのです。
2.ディープラーニングとは
ディープラーニングも機械学習の一つで、教師あり学習・教師なし学習・強化学習のすべてに適用できます。
具体的には分類に使う基準値をコンピューター自らが作り上げ、対象のデータ群を分類していく方法です。
分類のための基準値を特徴量といいます。
この特徴量を自ら作り上げることが可能で、人が特徴量設計をおこなう必要がないのがディープラーニングの特徴です。
3.強化学習とディープラーニングの違い
強化学習と、ディープラーニングの違いは下記のようになります。
- 強化学習:学習の過程で人間の力が必要な技術
- ディープラーニング:学習の過程で人間の力を必要としない技術
つまりディープラーニングのほうが、より人間の思考に近い結果を生み出す技術だといえるでしょう。
 強化学習とはなにか徹底解説|導入のメリットや4つの活用事例も紹介
強化学習とはなにか徹底解説|導入のメリットや4つの活用事例も紹介
強化学習の流れ

強化学習の構築手順として、4つのステップを理解しましょう。
- 環境を作る
- 報酬を定義する
- エージェントを作成する
- エージェントの学習と検証を開始する
1.環境を作る
まずは、学習をするエージェントが動作するための環境を定義します。
環境は、実際に存在する物理システムか、仮想の空間であるシミュレーション環境のどちらかで準備をします。
このように強化学習は幅広い環境で適用できるため、多岐に渡る分野のデータ分析に用いられます。
2.報酬を定義する
エージェントの行動により変化した状態と、その状態に対しての報酬を定義していきます。
状態とは、エージェントの行動による結果のことです。
その結果に対しての評価を、報酬といいます。
報酬の定義は最初から完成させることが難しいため、強化学習を進める過程で、何度も定義していくことになります。
3.エージェントを作成する
環境と報酬の定義が完了したら、エージェントを作成します。
エージェントは、
- 方策
- アルゴリズム
の2つで構成されています。
方策とは別名はポリシーともいい、環境の状態により、取るべき行動を定義することです。
アルゴリズムとしてはQ-LearningとSARSA、モンテカルロ法のいずれかが採用されます。
3つのアルゴリズムについて詳しくは後述します。
4.エージェントの学習と検証を開始する
定義した環境内で、エージェントの学習を開始します。
学習の流れは、以下のとおりです。
- 方策に基づいて行動する
- 変化した環境に対して、報酬を受け取る
- 受け取った報酬により方策を調整する
- 新たな方策に基づいて行動する
この流れを繰り返すことでエージェントが学習していきます。
強化学習はサンプル効率が低く、多くの結果が必要です。
アプリケーションによっては、この過程だけで数日必要になります。
プログラミング未経験でエンジニアを目指すことに不安を感じますよね。
そんな方には、基礎からプログラミングが学べる【DMM WEBCAMP】がおすすめです。
【DMM WEBCAMP】では、初心者のために開発した独自のカリキュラムが用意されており、基礎から確実にプログラミングスキルを身につけられます。
また転職保証付きのプランもあり、プログラミング学習も転職活動も安心して取り組めます。
厚生労働省認定のコースでは、高いスキルが身につく上、受講料最大56万円のキャッシュバックもついてきます。
是非あなたのライフスタイルに合ったプランを見つけてください。
「今の働き方に不満はあるけど、日々の業務が忙しくてゆっくり考える時間がない…」
そんな悩みを持つ方に向けて【DMM WEBCAMP】では無料のキャリア相談を実施しています。
ビデオ通話で相談をすることができるため、仕事で忙しい方でもスキマ時間に気軽にカウンセリングを受けることも可能です!
プロのキャリアカウンセラーと一緒に、今後のキャリアについて考えてみませんか?
強化学習の報酬を最大化にするためのアルゴリズム

こちらでは、強化学習のアルゴリズムについて解説します。
主に3つのアルゴリズムが存在しますので、それぞれの特徴を理解しておきましょう。
- Q-Learning
- SARSA
- モンテカルロ法
1.Q-Learning
強化学習の中で一番多く採用されるのが、Q-Learning、別名Q学習です。
Q-Learningでは、Q関数という行動価値関数を学習し、方策を再定義していきます。
Q関数とは、ある状態下で、一定の行動を取った場合の報酬を予測する計算式です。
Q関数によりある状態でエージェントが取る行動を事前に複数検証したうえで、より報酬が多い方を選択していきます。
2.SARSA
SARSAでは、Q-Learningと同じく、Q関数を学習します。
Q-Learningとの違いは、実際に行動した結果を用いた学習方法である点です。
Q-Learningでは、複数のケースを事前に予測したのちに最善の行動を取りますが、SARSAでは行動が先で、その結果により方策の再定義がおこなわれます。
3.モンテカルロ法
モンテカルロ法とは、大量の入力値をエージェントに与え、報酬を平均化し期待値を計算する手法です。
Q-LearningやSARSAと異なる点は、一回の入力や出力に対して方策の再定義をするのではなく、一定の報酬に達するまで行動をしつづけることです。
とくに、行動の評価方法が明確に定まってない場合の検証に向いています。
強化学習の事例3選

下記3つは、強化学習の導入によって業務の効率化に成功しました。
- 株式会社DeNAの提供するオンラインゲーム
- レコメンド機能
- AlphaGo
順番にみていきましょう。
1.株式会社DeNAの提供するオンラインゲーム
株式会社DeNAは、オンラインゲームの逆転オセロニアにおいて、顧客体験の向上を目的として、強化学習を活用しています。
強化学習を活用している分野は、
- プレイヤーサポート
- ゲームバランスの調整サポート
の2つです。
各プレイヤーの対戦データをリアルタイムで分析することで、最適な練習相手となることや、バランスの良い新キャラクターをプランニングします。
大量のデータ分析を人の手でおこなうのは難しいため、強化学習による方法が採用されています。
2.レコメンド機能
オンラインショッピングや動画サービスのレコメンド機能に、強化学習が使われています。
例えば、Netflixでは、流行・視聴率・離脱率などのデータをリアルタイムで学習していくことで、ユーザーに最適なコンテンツを表示しています。
集めたデータを作品作りなどに活かすこともでき、強化学習を利用するメリットの一つとしてあげられます。
3.AlphaGo
AlphaGoは、2016年に誕生した囲碁AIで、プロの棋士を相手に数々の勝利をおさめました。
使われている技術は、ディープラーニングと強化学習を組み合わせた深層強化学習です。
具体的には、
- ディープラーニング技術により、対戦相手を徹底的に模倣する
- 強化学習により、模倣した対戦相手(自分自身)との対戦を繰り返す
このような技術を使い、圧倒的な強さを身につけました。
他の種目などでも応用ができることから、今後に期待がかかる技術の一つです。
強化学習の将来性

株式会社アイ・ティ・アールは、機械学習プラットフォーム市場が44.0%増と大きく伸びていることを発表しました。(出典:プレスリリース|株式会社アイ・ティ・アール)
強化学習を含めた機械学習の市場が年々拡大しており、注目されていることがわかります。
とくに強化学習は、◯✕の線引きが難しい判断をくだすことに長けています。
他の学習方法とは異なる役割を担っていることから、機械学習の需要に比例して強化学習のニーズもますます高まっていくことでしょう。
強化学習を学べるおすすめの書籍3選

強化学習について詳しく学びたい方へ向けて、おすすめの書籍をご紹介します。
- 「強化学習」を学びたい人が最初に読む本
- 現場で使える!Python深層強化学習入門 強化学習と深層学習による探索と制御
- 強化学習アルゴリズム入門
順番にみていきましょう。
1.「強化学習」を学びたい人が最初に読む本
強化学習を学びたい、初心者の方向けに書かれた書籍です。
こちらをお読みいただくと、強化学習の基本的な理論と実装方法法が理解できます。
ロボットの動きをアニメーションで確認できるなど、機械学習についてまだ詳しくない方にも優しく書かれているのが特徴です。
2.現場で使える!Python深層強化学習入門 強化学習と深層学習による探索と制御
こちらの書籍は、深層強化学習の開発手法について書かれたものになります。
構成として、
- 深層強化学習の概要
- 強化学習や深層強化学習の基礎
- パズル問題などの応用例
- データの生成方法
を解説しています。
深層強化学習を学びたい理系の学生やエンジニア向けの書籍です。
3.強化学習アルゴリズム入門
こちらの書籍は、平均値の計算という観点から強化学習の原理を解説しています。
強化学習の基本である、
- 価値
- 探索
- マルコフ性
がわかりやすく説明されています。
専門用語を避け、中高生で習う平均を活用しているので、文系の方にもわかりやすい書籍です。
まとめ:強化学習の特徴をしっかりと理解しよう
本記事では、強化学習の基本や他の学習方法との違いについて紹介しました。
- 強化学習とは、機械学習の一つで、大量のデータを必要としない学習方法である
- 強化学習では、行動とその評価により学習していく手法が使われている
- 強化学習の事例として、囲碁AIであるAlphaGoやネットサービスのレコメンド機能がある
強化学習の技術は、これからますます身近に感じられるでしょう。
それぞれの機械学習の違いをしっかりと理解して、今後の学習に励んでください。














