
PythonのHTMLパーサーを使ってHTML解析する方法について解説!サンプルコード付き

「HTMLパーサーを使ってHTMLを分析したいけれど、どうしたらいいんだろう?」
「Pythonを使ってHTMLパーサーを操作する方法について知りたい」
上記のような疑問を抱えている方も多いのではないでしょうか?
Pythonに搭載されているクラスやライブラリを利用することで、HTMLのタグや値を取得できます。
今回、WEBCAMP MEDIAでは、PythonのHTMLパーサーを使ってHTML解析する方法について解説していきます。
- HTMLパーサーとは
- HTMLパーサーの使い方
- BeautifulSoupの使い方
以上の項目に沿って説明します。
この記事を読むことで、Pythonを使ってHTMLのタグや値を取得できるようになるので、ぜひチェックしてみてくださいね!
HTMLパーサーはHTMLの情報を取得・変換できる
パーサーとは、プログラミング言語のように規則性のある文章やデータから、任意のデータを取得して変換することです。
そのためHTMLパーサーは、HTMLファイルから特定のタグや値をパースするための処理になります。
HTMLファイルをパースするには、PythonやJavaScriptのようなプログラミング言語を使って実現可能です。
また、HTMLパーサーは情報を変換するだけでなく、Webサイトから自分の得たい情報を効率的に集めることができます。このような処理をスクレイピングと言います。
Pythonを利用したHTMLパーサーの使い方
Pythonには、HTMLParser(HTMLパーサー)というHTMLをパースするためのインスタンスが用意されています。
Pythonファイルを作成し、 HTMLParserをimport処理で読み込むことで、HTMLをパースできます。
Pythonを利用したHTMLパーサーの使い方について解説していきます。サンプルコードを使うのでPython初心者の方でも実装可能です。
サンプルコード
from html.parser import HTMLParser
class MyParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("開始タグは", tag,"です。付属されている属性は",attrs,"です")
def handle_endtag(self, tag):
print("終了タグは", tag,"です")
parseTag = MyParser()
parseTag.feed('<head><meta charset="utf-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><link rel="stylesheet" href="css/test.css"><title>test</title></head>')HTMLParserをMyParserクラスに継承します。そうすることで、HTMLParserに格納されている関数を利用できるようになります。
MyParserクラスに入力している関数の役割は下記になります。
- handle_starttag関数:開始タグに関する情報を取得する関数。第一引数で開始タグの名前、第二引数で開始タグの属性と値を取得できる。
- handle_endtag関数:開始タグに関する情報を取得する関数。
MyParserクラスをparseTag変数へ代入し、feed関数の引数にパースするためのタグを入力することで値を取得できます。
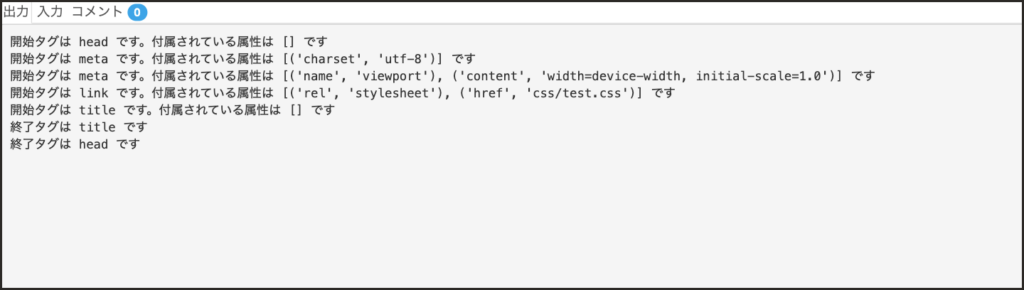
実行結果
BeautifulSoupを使ってHTMLをパースする方法
BeautifulSoupは、HTMLから任意のデータを取得できるPythonのライブラリです。
BeautifulSoupを使うことで、公開されているWebサイトのURLから任意のデータを取得できます。
今回は、BeautifulSoupを使ってHTMLタグに入力されている値をパースする方法について、サンプルコードを用いて解説します。
サンプルコード
from MySoup import BeautifulSoup
html_list = ' <body><h2>タイトル</h2><p>テスト</p></body>'
html_parse = BeautifulSoup(html_list, 'html.parser')
print('h2: ', html_parse.h2.string)
print('p: ', html_parse.body.p.string)importでBeautifulSoupを取得し、MySoupという名前で利用します。
BeautifulSoupの引数に、パースしたいHTMLの情報とhtml.parserを入力することで情報を取得できます。
print関数の第一引数に取得したいHTMLタグを入力し、第二引数はhtml_parseで取得したタグ情報の中から、stringプロパティを使って文字情報を取得しています。
上記の流れにより、h2タグの「タイトル」という文字とpタグの「テスト」という文字をパースできるのです。
HTMLパーサーを使ってサイト分析に役立てよう
今回、WEBCAMP MEDIAでは、PythonのHTMLパーサーを使ってHTML解析する方法について解説してきましたが、いかがでしたでしょうか。
PythonのHTMLパーサーを使うことで、HTMLファイルないから必要な値を探す手間が省けます。また、BeautifulSoupを使いこなせるようになると、Webサイトの解析にも役立ちます。
また、この記事をきっかけにPythonを学んでみたいと思った方は、下記の記事から学習方法を見てみることをおすすめします。
Pythonを学習する流れを4ステップで解説!おすすめの本5選や学ぶポイントも紹介
ぜひ参考にしてみてくださいね!